How Many Ad Variations To Test: Find Winners Faster
Jump to a section
- The Ad Testing Paradox More Variations More Problems
- Building Your Testing Framework From Objective to Hypothesis
- Finding Your Number Budget and Statistics
- A Phased Approach Pilot Testing vs Scaling Winners
- The Special Case of High-Velocity Video Ad Testing
- Operationalize Your Testing with Sovran Automation

You launch a batch of new ads. Maybe it’s Meta. Maybe TikTok. You’ve got fresh hooks, a few CTAs, two visual styles, and a spreadsheet that feels reassuring right up until the data comes in.
A few days later, nothing is clear. One ad has cheap clicks but no downstream quality. Another looks strong early, then fades. A third barely got delivery. Half the set never gathered enough signal to tell you anything useful.
That’s the main problem behind the question of how many ad variations to test. Teams aren’t short on ideas. They’re short on clean answers.
The fix isn’t a magic number. It’s a framework that adapts to your budget, your stage of testing, and the amount of data each variation needs before you trust the result.
The Ad Testing Paradox More Variations More Problems
A common mistake looks productive on the surface. A team builds a big batch of ads, uploads everything at once, and assumes more shots on goal will automatically produce a winner.
It often does the opposite.

When too many ads enter one test, budget gets fragmented. Delivery becomes uneven. Analysis gets muddy because multiple things changed at once. You finish the cycle with activity, not insight.
That’s the paradox. More variation can create less clarity.
Why volume alone breaks tests
Direct Agents makes the strongest version of this point. Their analysis argues that quality-focused testing with 8 to 16 thoughtfully crafted variations outperforms mass testing of 100+ rushed attempts, and that focused work on major drivers like hooks and CTAs can produce conversion rate gains of up to 30% when those basics are optimized first (Direct Agents on quality-focused ad testing).
That tracks with what experienced buyers see in-platform. A rushed pile of weak ideas doesn’t create optionality. It creates noise.
Practical rule: More ads only help when each variation is distinct enough to teach you something and funded well enough to earn a fair read.
The teams that move fastest usually don’t test the most assets. They test the most intentional assets.
What works instead
A better approach starts smaller and sharper.
You pick a clear control. You decide what single thing you’re trying to learn. Then you build a limited set of variations around that question. Instead of asking the platform to evaluate everything at once, you ask it one useful question at a time.
That’s how you get from “we launched 14 ads” to “the UGC hook beat the polished opener” or “the direct CTA improved conversion quality.”
The rest of this article follows that logic. Not one fixed number, but a working system for choosing the right number of ad variations for the test in front of you.
Building Your Testing Framework From Objective to Hypothesis
Good testing starts before anyone opens Ads Manager.
Most weak tests fail at the planning stage. The creative might be fine. The campaign setup might be fine. What’s missing is a clear reason for the test to exist.
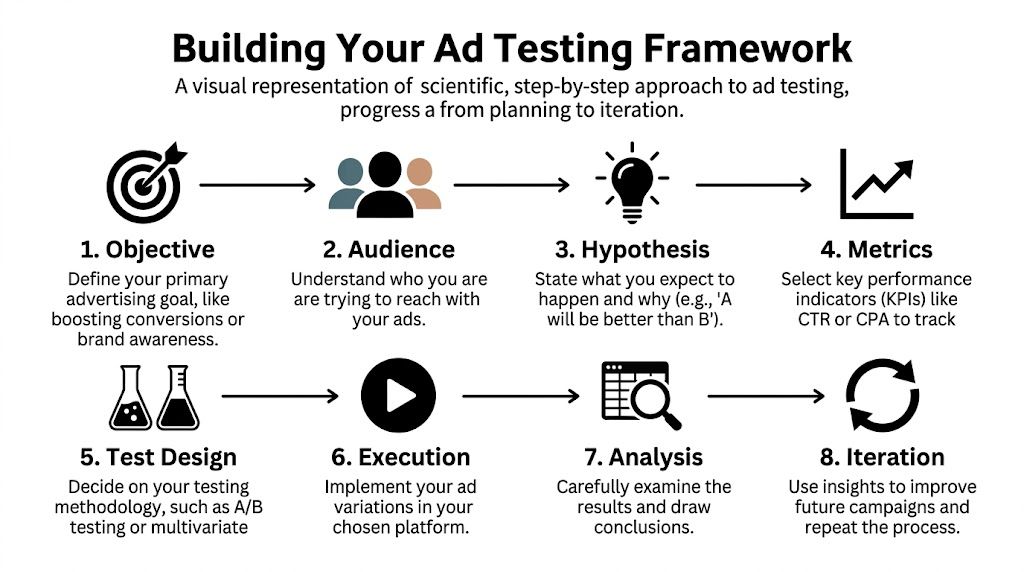
Start with one job for the test
An ad test should answer one business question.
That question might be about lowering CPA. It might be about improving ROAS. It might be about getting a stronger hold rate in the first seconds of a video. But it needs to be singular.
If you try to test for everything at once, you end up making trade-offs you can’t interpret later.
A useful way to frame the objective is:
- If you’re prospecting: Focus on the part of the ad that earns attention and qualified clicks.
- If you’re retargeting: Focus on the part that resolves objections or improves conversion intent.
- If you’re scaling a known angle: Focus on fatigue resistance and iteration, not broad discovery.
The objective shapes the number of variations you should create. Broad discovery can support more range. Tight optimization needs more control.
Turn the objective into a real hypothesis
A hypothesis forces discipline.
Instead of saying “let’s test some new creatives,” say what you believe:
- Audience-native hypothesis: A UGC-style opening will outperform a polished brand intro because it feels more native in-feed.
- Offer-framing hypothesis: A benefit-led headline will beat a feature-led headline because the audience needs immediate relevance.
- Conversion hypothesis: A direct CTA will outperform a softer CTA because the traffic is already problem-aware.
That gives the test a clear pass-fail structure.
A good hypothesis names the variable, the expected direction, and the reason.
You don’t need academic language. You need a claim you can prove or reject.
Break the ad into testable parts
Most paid social creatives are easier to test when treated as modular units.
Think in blocks:
- Hook: The first message or visual pattern interrupt.
- Body: The explanation, proof, demo, or narrative.
- CTA: The action prompt and closing frame.
Marketers often call five completely different ads “five variations.” They aren’t really variations if each one changes the hook, the body, the CTA, the pacing, and the format at the same time.
That kind of test can still find a winner. It usually can’t tell you why it won.
Isolate the variable before you scale the matrix
Isolation is what makes results actionable.
If you hold the body and CTA steady and only change the opening, you can attribute the outcome to the hook with much more confidence. If you change the CTA only, you can judge CTA effect without inventing a story about the whole ad.
Don Heesh’s testing guidance in the verified data supports this logic. Start with a small set, isolate one element at a time, and expand only after you have a signal.
A simple progression looks like this:
- Pick a control ad that already represents your current best thinking.
- Choose one variable to test. Hook is usually the best starting point for video.
- Create a small set of alternatives around that one variable.
- Keep audience, placement, and offer consistent so the read is usable.
- Document the hypothesis in plain language before launch.
That last point sounds basic. It matters more than is commonly understood.
Write down what each variation is supposed to prove
Naming discipline improves analysis.
When a team labels assets with vague names like “new v3 final” or “UGC 2 updated,” it gets harder to connect outcome to idea. Strong naming tells you the angle, variable, and version.
A useful naming structure might include:
- Angle
- Variable under test
- Version
- Audience if relevant
That makes post-test review faster and cleaner.
For a deeper planning process, this framework on creative testing for Meta ads is useful because it pushes the work upstream, where strong tests are built.
Prioritize the heavy hitters first
Not every part of the ad deserves equal testing effort.
If the campaign is underperforming, start where the greatest influence typically lies:
- Openers and hooks when watch-through is weak
- Headlines and framing when people click but don’t convert
- CTAs and closing language when the ad gets attention but stalls at action
The trap is spending hours tweaking tiny visual details before the fundamentals work.
Test the part most likely to change behavior, not the part that’s easiest to edit.
That mindset keeps the number of ad variations under control. You don’t need endless combinations when the actual issue is still unresolved at the hook or CTA level.
Finding Your Number Budget and Statistics
The practical answer to how many ad variations to test sits between two constraints.
First, your budget. Second, the amount of data each variation needs before you can trust the result.
If either constraint gets ignored, the test breaks.
Why 3 to 5 variations is the default starting range
For most campaigns, 3 to 5 ad variations per ad set is the most stable starting point. AdManage’s framework ties that range to a clear reason: it balances diversity with enough budget and delivery for each ad to get a fair read. Their analysis also notes that underpowered tests with too many variants can create 40% false positives, and that Meta campaigns testing 3 to 5 variants achieved 15 to 25% higher ROAS lift than single-ad baselines (AdManage on how many creatives to test).
That’s the range I’d treat as default until the account gives you a reason to deviate.
Not because 3 to 5 is magical. Because it’s usually enough to compare meaningful alternatives without starving each one.
Budget fragmentation is what kills most tests
The easiest way to ruin a test is to ask a small budget to support too many ideas.
If you test 15 variations in one ad set and only a few of them gather meaningful delivery, you don’t have a broad test. You have a distorted one. The platform is making early decisions before your data is mature enough to support them.
A leaner test does two things better:
- It gives each variation enough spend to produce interpretable outcomes.
- It reduces the odds that weak distribution patterns make you kill a potentially useful concept too early.
This is why “we can make more ads” isn’t the same as “we should launch more ads now.”
Statistical needs set the floor
The budget side tells you what’s feasible. Statistics tell you what’s credible.
You need enough evidence per variation to separate signal from random movement. If the campaign doesn’t have enough click or conversion volume to support multiple ads at once, the right answer is fewer variations, not more patience with a broken setup.
A practical planning habit is to define the evidence threshold before launch, then back into the number of variants your budget can sustain. If that number is low, accept the limit and run sequential tests.
You can use a tool like the creative testing calculator to pressure-test whether your planned variation count is realistic for the spend and volume available.
A simple decision table
Use this as a working rule set, not rigid law.
| Daily Ad Set Budget | Recommended Variations per Ad Set | Primary Goal |
|---|---|---|
| Low budget | 2 to 3 | Get a clean directional read without spreading spend too thin |
| Moderate budget | 3 to 5 | Compare a few meaningful alternatives with enough support for each |
| Higher budget | 3 to 5, then expand in separate structured batches | Increase discovery without collapsing test quality |
The key isn’t the label on the budget tier. It’s whether each variation can gather enough evidence to earn a decision.
Match variation count to campaign stage
A discovery campaign and a mature scaling campaign shouldn’t use the same testing shape.
Here’s the difference that matters:
- New campaign: Fewer, broader concept tests. You’re trying to find a viable angle.
- Mid-stage campaign: Controlled iterations on a known concept. You’re refining what already has traction.
- Scaling campaign: Separate small batches that test around the winner without disrupting delivery.
That’s why a single universal answer to how many ad variations to test usually fails in practice. The same account can need different counts in different moments.
What to do when budget is tight
If the budget is tight, compress the scope of the question.
Don’t test several angles, several formats, and several CTAs all in one shot. Choose the one decision that matters most now. Then build the smallest test that can answer it.
That usually means:
- one control
- one or two challengers
- one variable changed
- one clear success metric
That’s less exciting than launching a huge creative pack. It’s far more useful.
When the account can’t support breadth, buy clarity instead.
The strongest operators stay honest about what their spend can validate. They don’t ask a small test to produce enterprise-level certainty.
A Phased Approach Pilot Testing vs Scaling Winners
Testing works better when you separate learning from scaling.
Too many teams mix those jobs together. They launch unproven ads at full intensity, read early movement as truth, and then either scale too soon or kill a concept before it had a fair chance.
A phased structure solves that.
Phase one is the pilot
The pilot exists to find signal, not to maximize output on day one.
That means keeping the setup lean. Use a small number of deliberate variations built around a focused question. Let them run under stable conditions. Resist the urge to make midstream edits because one ad had a good morning.
The benchmark that matters here is significance. New Age Agency’s guidance is clear: at least 100 conversions or 1,000 clicks per variant, with a minimum run time of 5 to 7 days, is the threshold for avoiding misleading conclusions from random fluctuation (New Age Agency on A/B testing significance).
That single rule eliminates a lot of bad decisions.
How to know a pilot is done
A pilot should graduate only when it has enough time and enough volume.
The usual exit checks are simple:
- Time requirement: The test has completed the minimum run window.
- Volume requirement: Each relevant variation has gathered enough clicks or conversions to support a credible read.
- Clean setup: The variable under test was isolated.
- Decision clarity: You can explain why one version won without guessing.
If one of those is missing, the test probably needs more time or a simpler design.
For teams iterating heavily on short-form creative, this guide on video ad iteration strategy is useful because it treats iteration as a sequence of controlled rounds rather than one giant launch.
Phase two is controlled expansion
Once a concept proves it can clear the pilot, expand around the winner.
Many teams go wrong by taking the winning ad and stopping testing. That wastes the strongest thing the pilot gave you, which is a validated direction.
A better move is to keep the winning core and rotate targeted variants around it:
- a new hook on the same body
- the same hook with a different CTA
- the same narrative with a different proof device
- a tighter cut for feed speed
That turns one winner into a cluster of informed follow-ups.
A winner isn’t the end of testing. It’s the point where testing gets more efficient.
Why sequential beats chaotic
Sequential testing has one big advantage. It protects the integrity of what you learned.
If the pilot tells you that a certain angle works, your next round should build on that angle in a disciplined way. Don’t reset the board with a random batch of unrelated concepts unless the account needs a fresh discovery cycle.
This phased method also reduces emotional decision-making. Teams stop overreacting to tiny swings because they’ve already defined what counts as enough evidence.
That alone improves media discipline.
The Special Case of High-Velocity Video Ad Testing
Video breaks a lot of generic ad testing advice.
A static ad usually asks one visual to do most of the work. A video asks the opening seconds, pacing, scene order, captions, proof, and CTA to work together across time. That creates more places for performance to rise or collapse.
So when marketers ask how many ad variations to test for video, the usual “just test 3 to 5 creatives” advice is incomplete.
The real unit of testing is often the angle, not the full video
If you compare five completely different videos, you may find a winner. You usually won’t know whether the win came from the angle, the hook, the edit rhythm, or the CTA.
For video, the cleaner approach is often modular. Hold the angle steady, then vary the opening or the close. That lets you test where the difference is happening.
This is especially important on Meta and TikTok, where the first seconds of the ad often decide whether the rest of the creative gets a chance.
Why video needs its own variation count
There’s a real knowledge gap here. The verified data explicitly notes that generic benchmarks don’t fully answer how many video-specific variants you should test. It also points to a practical starting point: because Meta needs 2 to 3 conversions per day per ad set for signal, 4 to 6 video variants per ad set is a more realistic base for many video tests than a flat carryover from static creative advice (video-specific variation gap discussion).
That doesn’t mean every account should launch six videos at once.
It means video often benefits from a structure like this:
- one angle
- several hook variants
- a limited set of CTA styles
- one consistent audience
That keeps the test focused on the parts of video most likely to swing results.
What to avoid in video tests
A few patterns create bad reads fast:
- Mixing formats in one decision set: If static and video compete directly, format can distort the result.
- Changing too many timeline elements at once: You can’t tell whether the hook or the middle of the ad did the work.
- Treating every edit as a new concept: Tiny edit changes can matter, but not all of them deserve first-round testing.
If you’re building a stronger production process around this, Mastering Social Media Video Production is a useful companion resource because it focuses on the practical side of producing social-first video assets that are testable.
In video, the question isn’t only how many creatives to test. It’s how many meaningful opening and closing combinations your budget can support.
A cleaner way to think about scale
Once a video angle proves itself, you can widen the matrix.
That’s when larger sets of modular variants make sense. Not at the start, but after the angle has earned the right to deeper iteration. For many teams, that’s the point where hook libraries, subtitle styles, CTA overlays, and alternate b-roll starts to matter.
If you want a practical process for that production challenge, this walkthrough on how to make 50 video ad variations fast is a useful reference.
Operationalize Your Testing with Sovran Automation
At some point, the bottleneck stops being strategy.
It becomes operations.
You know what to test. You know which variable matters. But now someone has to pull clips, recut openings, swap CTAs, apply subtitles, keep naming clean, preserve brand consistency, and get everything into the ad platform without turning the workflow into a mess.
That’s where most testing programs slow down.
The operational problem is bigger than editing
Manual production creates hidden drag:
- Asset chaos: Teams can’t quickly find the right clip, review, or proof point.
- Version creep: Nobody knows which opener belongs to which body.
- Naming inconsistency: Analysis gets slower because the ad names don’t reflect the test logic.
- Slow launch cycles: By the time the next batch is ready, the account has already lost momentum.
This is why many performance teams now pair testing discipline with automation in adjacent parts of the workflow too. Even outside paid social, marketers are leaning on systems for repeatable content production, which is part of why resources on AI generated social media posts have become useful context for understanding where operational efficiency is coming from.
What automation changes
The verified data points to a concrete benefit here. For high-velocity testing, sequential A/B testing remains the preferred method, and tools for bulk rendering can support 10x faster testing cycles. The same source notes that at $5K/day you can test 4 ads per $1K, scaling to 2 ads per $1K at $50K/day as algorithms optimize, and cites 20 to 30% win rates in modular tests versus 10% from manual iteration in that workflow context (CleverX guide to ad testing methods and best practices).
That matters because testing speed compounds. Faster cycles mean more clean learning loops. More loops mean a better chance of reaching a durable winner before fatigue catches up.
A practical example of this operating model is Sovran’s modular video ad rendering workflow. It tags uploaded assets into reusable Hook, Body, and CTA blocks, then bulk-renders combinations so teams can launch structured variants without rebuilding each ad by hand.
A short product walkthrough helps make the workflow concrete:
What this changes for the marketer
Automation doesn’t replace judgment. It removes repetitive production tasks so judgment has room to matter.
That changes the job in a useful way:
- You spend more time on hypotheses.
- You preserve cleaner test structure.
- You launch follow-up variants while the learning is still fresh.
- You stop losing days to edits that don’t add strategic value.
The result isn’t “more ads” for its own sake. It’s a tighter path from idea to evidence.
If your team is stuck between wanting more creative output and needing cleaner test results, Sovran is built for that middle ground. It helps turn existing video assets into modular Hook, Body, and CTA variations, keeps brand context organized, and reduces the manual work required to launch structured Meta and TikTok tests at speed.

Manson Chen
Founder, Sovran
Related Articles

Demographic Targeting: A Performance Marketer's Guide 2026

Who Is the Target Audience and Why It Matters
