Female Voice Emulator: A Marketer's Guide to AI Voiceovers
Jump to a section
- From Creative Bottleneck to Scalable Asset
- Choosing Your Synthetic Voice Model
- Preparing Your Data for High-Quality Output
- Tuning Performance and Generating Variations
- Evaluating Voiceover Quality Like a Creative Director
- Navigating the Legal and Ethical Minefield
- Integrating Voice Assets in a Modular Ad Pipeline

You've got approved scripts, cutdowns for Meta and TikTok, and a creative team asking the same question every growth team hits eventually: who's recording all these voiceovers?
That bottleneck gets expensive fast. One line change means a new session. One localization request means a new actor, new edit, new timing pass, and usually a delayed launch. When you're trying to test hooks, offers, and CTAs at speed, voice production can become the slowest part of the pipeline.
That's why the female voice emulator has become more useful than the name suggests. For marketers, it's not really about novelty or gender conversion. It's about turning voice into a reusable production asset that can move at the same speed as your edit system, caption workflow, and creative testing process.
From Creative Bottleneck to Scalable Asset
A few years ago, voice emulation was largely treated like a gimmick. It sat in the same mental bucket as voice filters, gaming effects, and one-off entertainment tools. That framing is outdated.
Voice emulation now fits directly into production. The category has shifted from novelty toward workflow software, with modern tools supporting exports like MP3, MP4, SRT, and VTT for localization, captions, and ad operations according to Voicemod's history of voice changers. That matters because ad teams don't need a funny filter. They need assets that drop into an editor, subtitle file, and delivery workflow without extra manual cleanup.

The practical shift is simple. A female voice emulator now sits closer to stock footage, templates, and caption presets than to a toy effect. Teams use it to generate alternate reads, localize scripts, swap tonal direction, and export deliverables without booking another session.
What changes in the ad workflow
When voice is generated inside the creative process instead of added at the end, a lot of friction disappears:
- Hook testing gets faster: You can render multiple opening lines with different delivery styles before media buyers need final picks.
- Localization becomes operational: Voice, captions, and cutdowns can move together instead of through separate vendors.
- Script iteration stops breaking timelines: Small offer updates don't force a full re-record process.
If your team is already creating high-quality video ads via AI, synthetic voice is usually the missing layer that makes the whole system fully modular.
Practical rule: If changing the first five seconds of a video still requires human scheduling, your production pipeline isn't modular yet.
A lot of marketers also make the mistake of treating voice as a final polish step. It's better to treat it as an editable component from day one, the same way you'd manage hooks, bodies, supers, and CTA cards. That's the logic behind modular systems for scaling ad creative production.
Choosing Your Synthetic Voice Model
The first real decision isn't which female voice emulator has the nicest demo. It's whether you need pre-built text-to-speech or a cloned voice.
Those are different production choices. One optimizes for speed and range. The other optimizes for ownership and consistency.
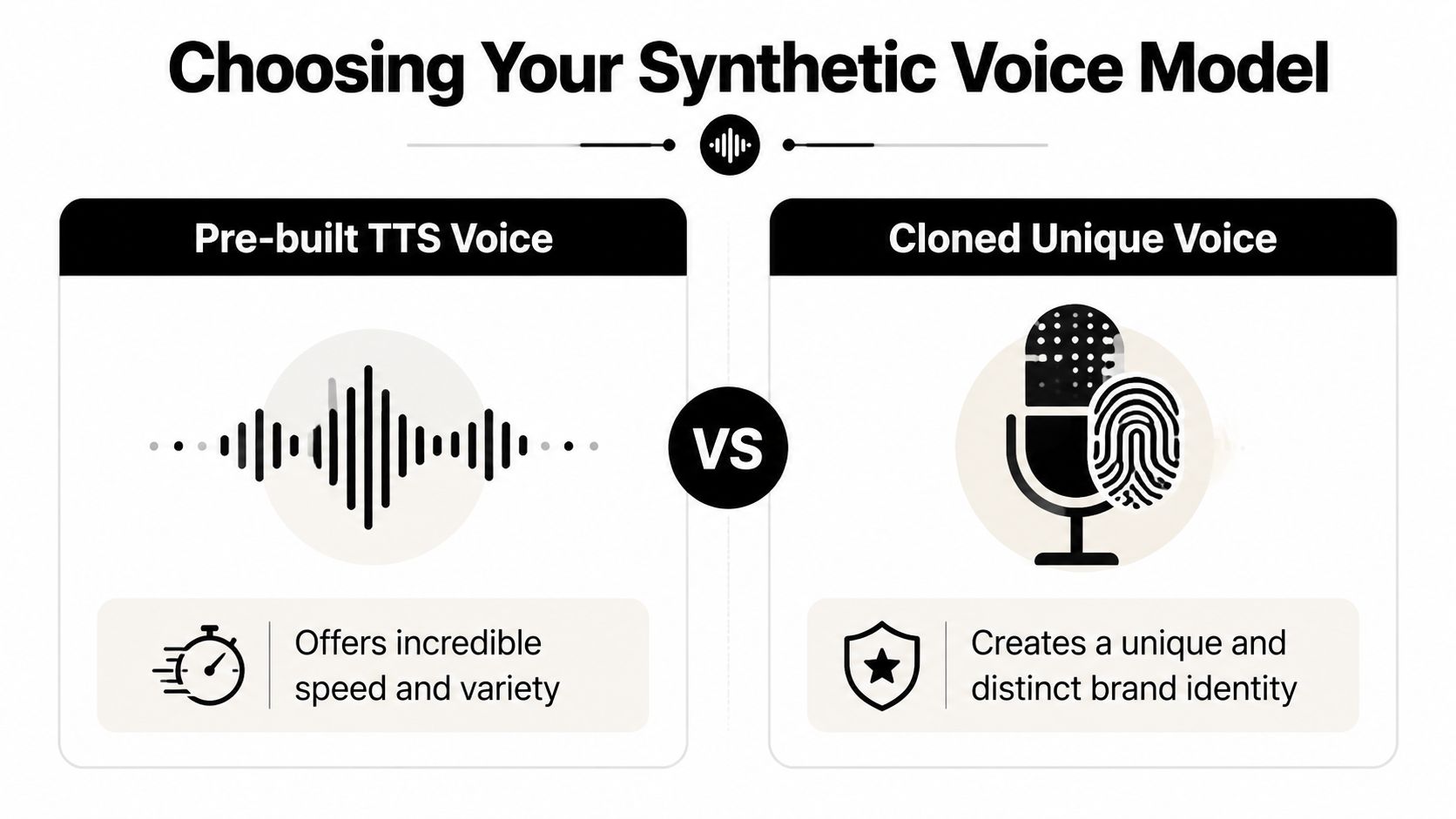
Pre-built TTS vs cloned voice
Some vendors now offer over 1,000 lifelike AI voices and support for 125+ languages, which shows how mature modern TTS has become for scalable production according to Speechify's overview of female voice changer tools. That scale changes the decision. You no longer choose pre-built voices only when quality is secondary. In many ad workflows, pre-built TTS is the efficient default.
| Model | Best for | Strengths | Trade-offs |
|---|---|---|---|
| Pre-built TTS | Fast testing, localization, creative volume | Immediate access, broad voice library, easy variation | Less exclusive brand identity |
| Cloned voice | Signature campaigns, recurring brand voice, owned sonic identity | Distinctiveness, consistency across campaigns | More setup, more approvals, higher legal sensitivity |
When pre-built TTS wins
If you're producing many variations across platforms, offers, or geographies, pre-built TTS usually makes more sense.
You can audition voices quickly. You can map one voice for direct-response hooks, another for tutorial content, and another for testimonial-style reads. You also avoid overcommitting to a single synthetic voice before you know what tone the audience responds to.
This is the safer option when:
- You need speed: The campaign is moving now, not after approvals and sample collection.
- You need breadth: Different products or funnels need different tonal profiles.
- You need localization: You want fast rollout across regions without rebuilding the system around one speaker.
A lot of teams start here using tools such as AI voiceover features for ad production, then standardize later once they've learned what kind of delivery works.
When cloning makes sense
Cloning is more strategic. It's not just “better TTS.” It's a brand asset decision.
If your ads rely on recognizability, repeated exposure, or a founder-style voice that audiences associate with the brand, cloning can create consistency that a rotating library of voices won't. But that advantage only matters if you're willing to manage it like a real asset, with consent documentation, approved usage terms, and clear replacement plans if the relationship changes.
Don't clone a voice because the feature exists. Clone when the voice itself is part of the brand system.
For most performance teams, the sequence that works is simple: start with pre-built TTS, identify the tonal lane that drives usable creative output, then decide whether a cloned voice is worth the operational overhead.
Preparing Your Data for High-Quality Output
Most bad AI voiceovers don't fail because the model is weak. They fail because the inputs are sloppy.
The female voice emulator only has two things to work with: source audio or source text. If either one is messy, the output will sound messy too. That's why good teams spend more time preparing than generating.
If you're cloning a voice
Cloning quality starts before you upload anything. You want recordings that sound boring from an engineering perspective. Clean room tone, consistent delivery, no background hum, no compression artifacts, no dramatic mic distance shifts.
Use this checklist:
- Record clean takes: Avoid echo, fan noise, keyboard clicks, and heavily treated audio from conferencing apps.
- Keep performance stable: Wild shifts in energy, accent, or mic position make the cloned model less predictable.
- Strip production effects: Don't feed the model music beds, mastering chains, or aggressive noise reduction.
- Label usage rights clearly: Every audio file should be tied to documented permission and approved scope.
A common mistake is using “best of” audio from old ads or podcasts. That material usually contains music, edits, breaths chopped too tightly, or performance styles that are too inconsistent to train a reliable synthetic voice.
If you're using TTS
With TTS, the script is the dataset. Many underestimate that.
Write for the ear, not the slide deck. AI narration performs better when sentences are shorter, syntax is direct, and emphasis is obvious from punctuation and structure. Long nested clauses tend to flatten delivery.
A practical script prep method:
Split by breath group
Break long lines into short spoken units. If a human would need a breath, the model probably needs a stop.Mark pronunciation risks
Brand names, product SKUs, and blended words often need phonetic guidance or alternate spelling.Write emphasis into the sentence
Front-load the important word. Don't hide the offer in the last clause.Use punctuation intentionally
Commas slow pace. Periods create authority. Question marks can over-lift tone if used carelessly.
The input standard that saves time later
If a line feels hard to read out loud, it will usually sound synthetic. Rewrite before you render.
Clean inputs save more time than any voice setting ever will.
I've seen teams waste hours trying to “fix” robotic delivery with speed and pitch controls when the underlying issue was script structure. The simplest test is still the best one: read the line aloud once. If you stumble, rewrite it.
Tuning Performance and Generating Variations
A usable output isn't the same as a persuasive read. The essential work starts after generation, when you direct performance.
Most female voice emulator tools now give you some combination of pacing, pitch, emphasis, style, or emotional control. That doesn't mean you should max them out. Good ad voice direction is usually subtle. The best outputs sound intentional, not overacted.

Direct each segment like a separate job
A hook, product explanation, and CTA shouldn't share the exact same delivery settings. They do different work.
Use a modular performance approach:
- Hooks need movement: Faster pace, sharper emphasis, and a little more energy can help the opening feel scroll-stopping.
- Body copy needs clarity: Pull the speed back. Prioritize intelligibility over excitement.
- CTAs need confidence: Slow slightly, reduce melodic variation, and make the action sound certain.
That's how you generate usable combinations instead of one long flat read. If you're building variation sets with an AI voiceover generator for ad workflows, create separate assets for each segment instead of one monolithic narration file.
Build a voice direction matrix
Here, creative teams can get systematic without becoming mechanical.
Create a small matrix for every campaign:
| Ad component | Direction | Common mistake |
|---|---|---|
| Hook | Urgent, clear, front-loaded emphasis | Talking too fast to understand |
| Problem statement | Conversational, grounded | Sounding like explainer software |
| Benefit line | Warm, assured | Overselling with exaggerated emotion |
| CTA | Direct, slightly slower | Ending with weak cadence |
Once you have that matrix, generate variants intentionally. Don't ask for “three versions.” Ask for “one energetic hook, one restrained hook, one neutral hook.”
A quick example helps:
- Hook A: brisk, punchy, high intent
- Hook B: calmer, more premium
- CTA A: direct and authoritative
- CTA B: softer, trust-building
That structure lets editors swap voice components the same way they swap headlines or end cards.
Later in the workflow, this kind of performance tuning becomes easier to standardize:
What usually doesn't work
The weak outputs are predictable.
Teams often push emotion too far, run every line at the same speed, or use one “pretty” voice for every audience and objective. That creates sameness. Performance ads need utility more than polish. A voice that sounds elegant but vague will lose to one that lands the message cleanly on a phone speaker.
Treat synthetic direction like casting plus line reading. Voice choice alone won't carry weak delivery.
Evaluating Voiceover Quality Like a Creative Director
Teams often review AI voice incorrectly. They ask whether it sounds realistic.
That's too low a bar. A voiceover can sound technically clean and still be wrong for the ad. Creative evaluation has to connect the voice to the job it's doing inside the asset.
Four ways to judge the read
I use four filters.
Brand alignment comes first. Does the voice sound like your brand would speak? A wellness brand, a finance app, and a mobile game might all choose a female voice emulator, but they shouldn't sound remotely similar.
Emotional fit matters next. The read has to match the intended response. Reassurance, urgency, authority, curiosity, and empathy are different jobs. If the emotion is off by even a little, the whole ad feels staged.
Then there's contextual plausibility. A scrappy UGC-style edit paired with a polished corporate narration usually feels fake. The tone has to match the footage, captions, and pacing of the cut.
The last filter is international nuance. At this stage, a lot of localization work falls apart.
Localization quality is not a language toggle
For global campaigns, the question isn't whether the tool can produce a female voice in another language. It's whether that voice can carry the right regional accent, age profile, and emotional tone for the market. Tools may support 100+ languages, but strong localization still depends on culturally believable performance, as noted by Maestra's discussion of female voice generation and localization nuance.
That means a technically correct translation can still miss. It may sound too generic, too formal, too theatrical, or unfamiliar in the target market.
A fast review framework helps:
- Mute the visuals first: Listen only for trust, clarity, and natural phrasing.
- Then watch on mobile: Check whether pacing survives small-screen attention spans.
- Review with native ears when localizing: Fluency isn't enough. You need audience plausibility.
- Compare against real ad references: Not studio demos. Real ads in your category.
What approval should actually sound like
Don't approve a read because nobody objects to it. Approve it because it supports the ad's intent.
The right synthetic voice doesn't just avoid sounding robotic. It makes the creative easier to believe.
That's a creative director standard, not an audio engineering standard. And it's the one that keeps synthetic voice useful instead of merely convenient.
Navigating the Legal and Ethical Minefield
A female voice emulator can accelerate production and still create unnecessary risk if your team treats it casually.
The convenience is exactly what makes it dangerous. Real-time voice changing, platform-ready exports, and easy switching between content formats are useful features. They also make impersonation and misuse easier if nobody sets rules. That's why concerns around consent, disclosure, and impersonation risk deserve attention, especially as these tools are marketed for calls, streaming, and content creation according to ElevenLabs' female voice changer page.

The rules brands should set before launch
If you're cloning or deploying synthetic voices in ads, establish written policy before the first render goes live.
Use a baseline checklist:
- Get explicit permission: If a real person's voice is cloned or closely modeled, secure written consent with approved use cases.
- Define where the voice can appear: Paid ads, organic content, customer support, live calls, and internal demos should not be bundled into one vague permission line.
- Document ownership and exit terms: If the relationship ends, define whether the brand can keep using existing assets.
- Set disclosure standards: Decide when synthetic voice should be labeled and make that rule consistent.
- Restrict high-risk uses: Ban deceptive impersonation, false endorsements, and any deployment designed to obscure who is speaking.
Why ethics is also performance strategy
This isn't just about legal exposure. It's about audience trust.
If a brand uses a synthetic voice in a way that feels evasive, manipulative, or too close to impersonation, the creative may still launch, but the trust cost shows up elsewhere. Customer sentiment, creator relationships, and brand credibility all get harder to recover than a delayed ad launch.
A useful internal test is simple: would your team be comfortable explaining the voice workflow publicly? If the answer is no, the process probably needs tightening.
For privacy-sensitive workflows, teams should also align with existing internal governance and published policies, including materials such as Sovran's privacy information.
Ethical voice use needs policy, not vibes.
The teams that avoid trouble aren't the ones with the fanciest AI stack. They're the ones that treat voice rights, disclosure, and audience trust as production requirements.
Integrating Voice Assets in a Modular Ad Pipeline
Once you've generated approved voice clips, the goal isn't to admire them. The goal is to operationalize them.
That means storing voice assets the same way you store hooks, product demos, testimonials, subtitles, and CTA cards. A female voice emulator becomes valuable when the output is modular, searchable, and reusable across many ad builds.
Build the asset library first
Separate your voice files by function, not by project folder name.
A practical structure looks like this:
- Hooks: Short opening lines grouped by offer, persona, or angle
- Bodies: Product explanation, pain-point narration, objection handling
- CTAs: Purchase prompts, signup pushes, trial language
- Localized variants: Market-specific reads with matching captions
- Alternate tonal versions: Premium, direct-response, creator-style, tutorial-style
That structure gives editors and buyers more freedom. Instead of reopening a full session to change one sentence, they can swap components.
Pair voice modules with visual modules
The strongest setup is a one-to-many system. One script branch can generate several reads. One read can pair with several visual edits. One CTA can close many different bodies.
Modular frameworks thus become practical, not theoretical. If your team already uses a system for recombining hooks, bodies, and offers, synthetic voice drops neatly into it. In a tool like Sovran, for example, teams can manage voiceover generation alongside other remixable ad components and apply the same logic used in a modular video ad framework.
A simple operating model works well:
- Generate voice assets by segment.
- Name them by function and tone.
- Pair each with corresponding subtitle files if needed.
- Load them into your edit system as reusable modules.
- Assemble variations for different audiences and placements.
- Retire weak reads, keep strong tonal patterns, and expand the library.
What this changes for the team
Editors stop doing avoidable rework. Strategists can request tonal alternatives without resetting production. Media buyers get more testable combinations. Producers spend less time coordinating pickups.
This is its primary value. A female voice emulator isn't just a way to make narration faster. It's a way to make creative iteration faster.
When voice becomes an asset class inside the ad pipeline, your team can test more angles without rebuilding every video from scratch. That's the difference between using AI voice as a feature and using it as infrastructure.
If your team is trying to turn scripts, cutdowns, voiceovers, and modular edits into a repeatable testing system, Sovran is built for that kind of workflow. It helps performance marketers organize assets, generate variations, and assemble high volumes of video ads without treating each new test like a brand new production job.

Manson Chen
Founder, Sovran
Related Articles

AI Talking Head Videos for Scaling Ad Creative

British Text to Speech: A Marketer's Guide for Ads
